










راز کشف آهنگ های جدید با اسپاتیفای
رکنا: اسپاتیفای با استفاده از الگوریتم های پیچیده، آهنگ هایی را به کاربران پیشنهاد می دهد که با علایق آنها سازگار باشد اما این الگوریتم ها چطور کار می کند؟

به گزارش رکنا، در دورانی که موسیقی به نامحسوسترین شکل ممکن با فناوری ادغام شده، اسپاتیفای با بیش از ۶۰۰ میلیون کاربر ماهانه، از تمام پلتفرمهای پخش موسیقی جلوتر است. دلیلش هم نه فقط بهخاطر کاتالوگ موسیقی عظیم این سرویس، بلکه سیستم پیشنهاد آهنگ مبتنیبر هوش مصنوعی آن است که خود را با علایق و تجربهی شنیداری منحصربهفرد تکتک کاربران تطابق میدهد.
دیگر گذشت زمانیکه برای پیدا کردن آهنگ مورد علاقه بعدی خود باید سراغ جدول پرفروشترین آلبومها یا پیشنهادهای دوستان میرفتیم. این روزها، یافتن تصادفی آهنگ موردعلاقه دیگر بیمعنی است؛ چراکه بهلطف رویکرد نوآورانهی اسپاتیفای، جادوی کشف موسیقی با الگوریتمهای پیچیدهای در هم آمیخته که تجربهی شنیداری ما را شکل میدهند.
الگوریتم اسپاتیفای همانند الگوریتم تیکتاک و شزم، سیستمی پیچیدهای مبتنی بر یادگیری ماشین است که با هر بار تعاملِ کاربر با این پلتفرم، هوشمندتر میشود. این الگوریتم با تحلیل عمیق دادههای رفتاری مخاطب، از جمله آهنگهایی که گوش میدهد، پلیلیستهایی که ایجاد میکند و هنرمندانی که دنبال میکند، پروفایلی شخصی و مطابق با سلیقهی موسیقی او میسازد. سؤال اینجا است که این الگوریتم پیچیده و فوقالعاده گرانبها که اسپاتیفای را از رقبایش متمایز کرده، دقیقاً چطور کار میکند؟
تحول اسپاتیفای از یک شرکت موسیقی به یک غول فناوری
اسپاتیفای با حدود ۶۱۵ میلیون کاربر فعال در ماه و کتابخانهای متشکل از بیش از ۱۰۰ میلیون آهنگ یک شرکت موسیقی فعال در حوزهی فناوری نیست، بلکه یک شرکت فناوری فعال در حوزهی موسیقی است. به بیان دیگر، اسپاتیفای به جای تولید موسیقی، پلتفرمی را توسعه داده است که به کاربران امکان میدهد به میلیونها آهنگ دسترسی داشته باشند.
اسپاتیفای، مشابه گوگل یا اینستاگرام، با جمعآوری دادهها و استفاده از آنها سعی میکند سلیقهی کاربران را پیدا و آنها را به استفاده از این پلتفرم و ماندن در آن تشویق کند. بهگفتهی این شرکت، روزانه صدهزار آهنگ، پادکست و کتاب صوتی در این پلتفرم آپلود میشوند و این فایلهای صوتی بهطور هوشمند و بهلطف الگوریتمها به کاربران پیشنهاد میشود.
جادوی الگوریتم اسپاتیفای
الگوریتم، دستوالعملی دقیق، گامبهگام و محدود است که برای حل مسئلهای خاص طراحی شده است. این دستورالعمل باید به گونهای باشد که هر فرد یا کامپیوتر، بتواند آن را بهطور دقیق دنبال کند و به نتیجهی مطلوب برسد. الگوریتمهای زیادی در اسپاتیفای در کنار یکدیگر کار میکنند، اما ما برای راحتی، تمام آنها را در قالب یک الگوریتم در نظر میگیریم.
این الگوریتم به تمام دادههای جمعآوریشده در اسپاتیفای دسترسی دارد:
سن کاربران
آهنگهایی که کاربران به آنها گوش میدهند.
شباهت بین آهنگهایی که هر کاربر گوش میدهد.
کاربران هنگام بارش باران یا شبها به چه آهنگهایی گوش میدهند.
حجم و تنوع این دادهها بسیار زیاد است و الگوریتم اسپاتیفای با دسترسی به این دادهها، تعامل مخاطب با محتوا و خود محتوا براساس نوع آهنگهایی که کاربر گوش میدهد و زمانِ صرف شده برای هر آهنگ، مورد بررسی قرار میگیرند. همچنین، الگوریتم در تحلیل محتوا، ویژگیهای مختلف آهنگ را مانند ژانر، تمپو، انرژی و سایر اطلاعات مرتبط با موسیقی را تحلیل میکند تا از این نتایج برای ساخت پلیلیستهای شخصیسازیشده مانند Release Radar و Discover Weekly استفاده کند.
بسیاری از افراد تصور اشتباهی از الگوریتم اسپاتیفای دارند و فکر میکنند این الگوریتم صرفا براساس ویژگیهای فنی آهنگ مانند سرعت، کلید و شباهت به آهنگهای دیگر عمل میکند. اما الگوریتم اسپاتیفای بسیار پیچیدهتر از آن است که فقط به ویژگیهای فنی آهنگ توجه کند و سعی میکند بفهمد شما چه نوع موسیقی را در چه شرایطی دوست دارید.
الگوریتم اسپاتیفای به ویژگیهای فنی آهنگ و محتوای آن توجه میکند
نهتنها اسپاتیفای، بلکه پلتفرمهای دیگری مانند آمازون و نتفیلکس نیز برای تبلیغ محصولات و پیشنهاد فیلمها، به این الگوریتم که به سیستم توصیهگر شناخته میشود، وابسته هستند. سیستمهای توصیهگر به دو دستهی «پالایش گروهی» (Collaborative Filtering) و «پالایش محتوامحور» (Content-based Filtering) تقسیمبندی میشوند.
پالایش گروهی
این روش با بررسی و تحلیل ترجیح کاربران با سلایق و رفتارهای مشابه، آهنگهای موردعلاقهی آنها را پیشنهاد میدهد. بهعنوان مثال، اگر دو کاربر به موسیقی جاز علاقهمند باشند و به دو آهنگ معروف Take Five و Take the 'A' Train گوش داده باشند، الگوریتم پالایش گروهی ممکن است با توجه به آنکه کاربر اول، آهنگِ What a Wonderful World را گوش کرده باشد، آن را به کاربر دوم پیشنهاد دهد.
از دیدِ روشهای پالایش گروهی، کاربرانی که در گذشته رفتار مشابهی داشتهاند، در آینده نیز رفتار مشابهی از خود نشان خواهند داد، بنابراین آهنگهای پیشنهادی را تنها با استفاده از دادههای کاربر تولید میکنند. یکی از مزیتهای این روش آن است که نیازی به تحلیل محتوا ندارد و میتواند بدون نیاز به دانستن مشخصات فنی آهنگهای مختلف، آنها را به کاربران علاقهمند پیشنهاد دهد.
بهطور دقیقتر، الگوریتم اسپاتیفای هنگام تحلیل نحوه تعامل کاربران با آهنگها و پلیلیستها، موارد زیر را بررسی میکند:
تاریخچه آهنگهای شنیدهشده: الگوریتم آنچه را که کاربران در گذشته گوش دادهاند ردیابی میکند تا آهنگ مورد علاقهی بعدی آنها را پیشبینی کند.
پلیلیستها و آهنگهای ذخیرهشده: آهنگهایی که کاربران به پلیلیستهای خود اضافه میکنند یا در کتابخانهی خود ذخیره میکنند، نشاندهندهی علایق موسیقیایی آنها است.
آهنگهای رد و تکرارشده: الگوریتم آهنگهایی که کاربران به طور مکرر رد میکنند یا دوباره گوش میدهند را نظارت میکند تا پیشنهادها را بهبود بخشد.
لایکها و اشتراکگذاریها: آهنگهایی که کاربران لایک میکنند یا با دیگران به اشتراک میگذارند، بهعنوان شاخصهای سلیقه تلقی میشوند.
پالایش محتوامحور
روش پالایش محتوامحور، برخلافِ پالایش گروهی، به رفتار کاربران توجهی ندارد و تنها به خود آهنگ توجه میکند. این روش، به جای بررسی حجم عظیمی از دادههای کاربران، محتوای آهنگهای پیشنهادی را بررسی میکند و به کاربران علاقهمند، پیشنهاد میدهد. بهعنوان مثال، اگر کاربری دو آهنگِ جاز گوش داده باشد، آهنگ دیگری در همین ژانر به او پیشنهاد خواهد شد.
فیلنرینگ مبتنی بر محتوا به جای بررسی حجم عظیمی از دادههای کاربران، محتوای آهنگهای پیشنهادی را بررسی میکند
با توجه به مجموعه تهیهشده از پرطرفدارترین آهنگهای اسپاتیفای در سال ۲۰۲۳، پالایش محتوامحور از ویژگیهای زیر برای آهنگهای پیشنهادی استفاده میکند:
تمپو (بیت در دقیقه - BPM): این ویژگی تعداد ضربان در دقیقه آهنگ را نشان میدهد و به ما میگوید که آهنگ سریع یا کند است. آهنگهای شاد معمولاً تمپو بالاتر و آهنگهای آرام، تمپوی پایینتری دارند.
رقصپذیری (danceability): آهنگهایی با امتیاز danceability بالا، معمولاً ریتمیک هستند و ساختار مناسبی برای رقص دارند.
شادابی (valence): این ویژگی میزان مثبت بودن یا خوشایند بودن آهنگ را نشان میدهد. آهنگهای با ضریب شادابی بالا معمولاً شاد و پرانرژی و آهنگهای با شادابی پایینتر معمولاً غمگین هستند.
انرژی: این ویژگی میزان انرژی و شدت آهنگ را نشان میدهد. آهنگهای پرانرژی معمولاً بلند، سریع و و پرسروصدا هستند، اما آهنگهای کمانرژی، آرام و ملایم هستند.
آکوستیک بودن (acousticness): احتمال آکوستیک بودن آهنگ را تخمین میزند. مقادیر بالاتر نشاندهنده حداقل استفاده از سازهای الکترونیک است.
سازی (instrumentalness): این ویژگی نشان میدهد که در ساخت آهنگ تا چه حد از سازهای موسیقی استفاده شده است. مقادیر بالا نشاندهنده حضور کم یا نبود خواننده در آهنگ است.
حضور مخاطب (liveness): این معیار، حضور مخاطب در ضبط آهنگ را نشان میدهد و آهنگهای اجراشده در کنسرت یا مکانهای شلوغ را از آهنگهای استودیویی متمایز میکند.
گفتاری (speechiness): میزان وجود کلمات در آهنگ را تشخیص میدهد. آهنگهایی که شامل رپ یا پادکست، امتیاز گفتاری بالاتری دارند.
کلید و مود (Key and Mode): این معیار، کلید موسیقی آهنگ و اینکه در حالت ماژور (معمولاً شاد) یا مینور (اغلب غمگین) قرار دارد را شناسایی میکند.
بلندی صدا (Loudness): حجم صدای کلی آهنگ که با دسیبل (dB) اندازهگیری میشود. این معیار بر برجستگی آهنگ تأثیر میگذارد.
این ویژگیها به الگوریتم کمک میکند تا شباهت بین آهنگها را پیدا کند و آهنگهای موردعلاقهی کاربر را به او پیشنهاد دهد. بهعنوان مثال، اگر کاربری بیشتر آهنگهای شاد با ضربِ تند و انرژی بالا گوش میدهد، الگوریتم میتواند آهنگهایی با این مشخصات مانند Despacito را به کاربر پیشنهاد دهد.
فرض کنید کاربری در اسپاتیفای ۵ آهنگ را پسندیده، اما ۵ آهنگ را دوست نداشته است. الگوریتم اسپاتیفای با استفاده از «رگرسیون لجستیک» (Logistic Regression)، «ماشین بردار پشتیبانی» (Support Vector Machine) و «آدابوست» (AdaBoost) آهنگهای موردعلاقهی کاربر را به او پیشنهاد میدهد. در ادامه، در مورد هر یک از این روشها در یادگیری ماشین صحبت میکنیم. اما قبل از آن یادگیری ماشین را به اختصار توضیح میدهیم.
نقش یادگیری ماشین در الگوریتم اسپاتیفای
یادگیری ماشین نهتنها به یادگیری چیزی، بلکه به فهمیدن و قدرت استدلال نیز مربوط میشود. فردی بهنام رامین را در نظر بگیرید که عاشق گوش دادن به آهنگهای جدید است و آهنگهای موردعلاقهی خود را براساس ژانر، گام یا تمپو، شدت و جنسیت خواننده، انتخاب میکند. برای سادگی، تنها به گام و شدت توجه میکنیم و موارد دیگر را در نظر نمیگیریم.
به نمودار نشان داده شده در تصویر زیر دقت کنید. گام یا سرعت آهنگ روی محور افقی از آهسته به سریع و شدت روی محور عمودی از آرام به بلند نشان داده شده است. آهنگهای موردعلاقهی رامین و آهنگهایی که آنها را نپسندیده است بهترتیب با نقاط سبز و قرمزرنگ نشان داده شدهاند.
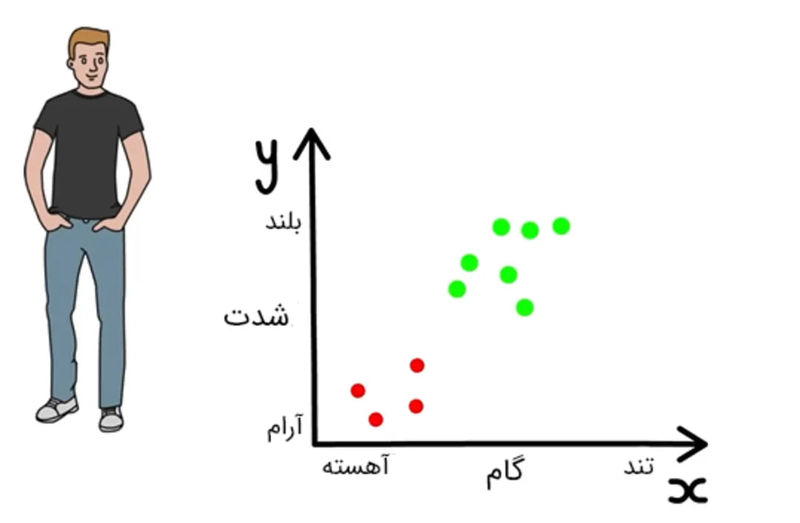
همانطور که در نمودار بالا مشاهده میکنید، رامین به آهنگهایی با سرعت بالا و شدت زیاد علاقه دارد و علاقهای به آهنگهای ملایم با شدت کم ندارد. او در ادامه آهنگ جدیدی را به نام A با گام تند و شدت بالا برای گوش دادن انتخاب میکند. این آهنگ با علامت ضربدر در تصویر زیر نشان داده شده است.
آیا رامین آهنگ A را دوست دارد؟ باتوجهبه مکان این آهنگ در نمودار، میبینیم آهنگ A، آهنگ موردعلاقهی او است. درنتیجه، با نگاه به آهنگهایی که رامین در گذشته گوش داده است، بهراحتی میتوانیم آهنگهای جدید را براساس علاقهی او دستهبندی کنیم. در ادامه، رامین به آهنگ دیگری به نام B گوش میدهد. این آهنگ را با علامت ستاره در نمودار نشان میدهیم. این آهنگ گام و شدت متوسطی دارد و بین دایرههای سبز و قرمزرنگ قرار گرفته است.
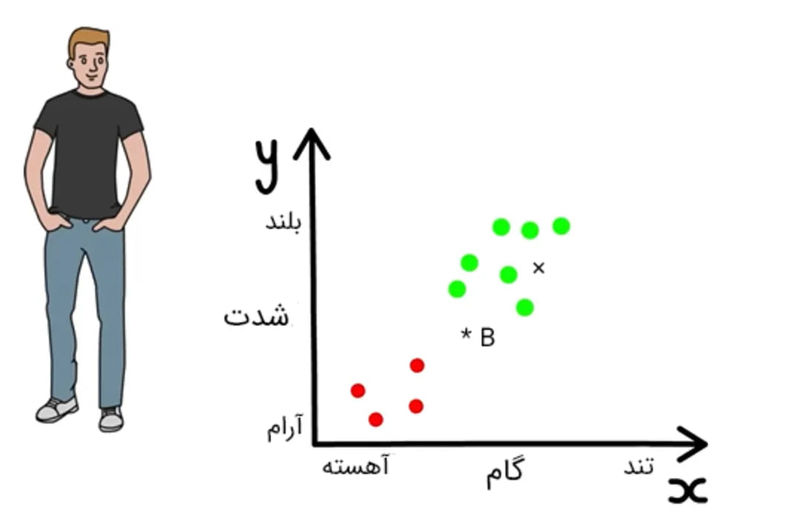
آیا رامین آهنگ B را دوست دارد؟ پاسخ به این پرسش دشوار است. اگرچه بهراحتی توانستیم آهنگ A را در دستهی آهنگهای موردعلاقهی رامین قرار دهیم، تصمیمگیری در مورد آهنگ B خیلی راحت نیست. اینجا، همان جایی است که یادگیری ماشین پا به میدان میگذارد. اگر دایرهای دورِ آهنگ B رسم کنیم، چهار نقطهی سبزرنگ و یک نقطهی قرمزرنگ، درون آن قرار میگیرند. اگر دنبالهروی اکثریت آرا باشیم، آهنگ B را میتوانیم در دستهی آهنگهای موردعلاقهی رامین قرار دهیم.
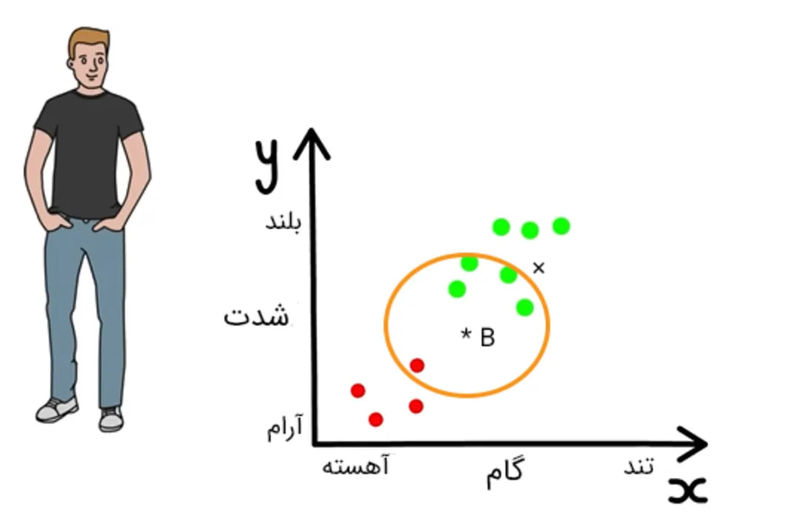
روش فوق، یکی از الگوریتمهای یادگیری ماشین و مثالی کوچک، میان الگوریتمهای بسیارِ یادگیری ماشین است. بنابراین، بههنگام برخورد با دادههای پیچیده مانند آهنگ B، یادگیری ماشین به کمک یکی از الگوریتمهای خود دادهها را بررسی و براساس آنها، مدلی برای پیشبینی میسازد. مدلِ ساخته شده، دادههای جدید را بررسی و پیشبینی لازم را انجام میدهد. هرچه تعداد دادهها بیشتر باشد، مدل ساخته شده دقیقتر خواهد بود. در اپلیکیشنی مانند اسپاتیفای با میلیونها آهنگ (داده) طرف هستیم، بنابراین الگوریتمِ بهکار رفته، بسیار دقیق است.
تا اینجا فهمیدیم یادگیری ماشین چیست و چگونه کار میکند. در ادامه، در مورد الگوریتم اسپاتیفای که با استفاده از روشهای رگرسیون لجستیک، ماشین بردار پشتیبانی و آدابوست کار میکند، توضیح میدهیم. برای آشنایی با این الگوریتم، در مورد هر یک از روشهای نامبرده صحبت میکنیم.
رگرسیون لجستیک
برای درک بهتر رگرسیون لجستیک، ابتدا به سراغ یک مفهوم سادهتر میرویم: رگرسیون خطی. فرض کنید میخواهیم رابطهی بین محبوبیت یک ژانر موسیقی در اسپاتیفای (مثلاً تعداد پلیهای ماهانه) و تعداد هنرمندانی را که در آن ژانر فعالیت میکنند، بررسی کنیم. در این حالت، میتوانیم از رگرسیون خطی برای رسم یک خط روند استفاده کنیم که نشان دهد با افزایش تعداد هنرمندان، احتمالاً محبوبیت ژانر نیز افزایش مییابد.
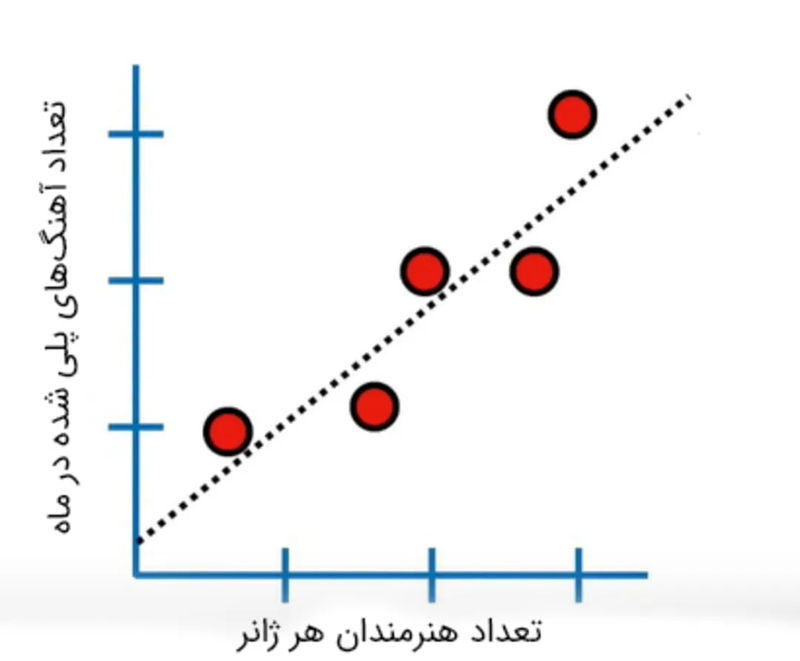
خط رسمشده اطلاعات زیادی به ما میدهد:
با محاسبهی R^2 میتوانیم میزان همبستگی را بین تعداد هنرمندان هر ژانر و تعداد آهنگهایی که ماهانه در آن ژانر پلی شدهاند، تعیین کنیم. هرچه مقدار R^2 بیشتر باشد، میزان همبستگی نیز بیشتر است.
با استفاده از خط رسمشده میتوانیم تعداد آهنگهای پلیشده در هر ژانر را با تعداد هنرمندان آن ژانر، پیشبینی کنیم.
در یادگیری ماشین با داشتن تعدادی داده میتوانیم رخدادی را پیشبینی کنیم، بنابراین، رگرسیون خطی نوعی یادگیری ماشین است. رگرسیون دیگری به نام رگرسیون چندگانه نیز داریم که در آن رابطهی بین یک متغیر عددی (وابسته یا هدف) و چندین متغیر مستقل را مدلسازی میکنیم.
فرض کنید میخواهید بدانید چه عواملی بر موفقیت یک آهنگ در اسپاتیفای (تعداد پخشها) تأثیر میگذارند. برای این کار میتوانید عواملی مانند ژانر آهنگ، تعداد دنبالکنندههای هنرمند و مدتزمان آهنگ را در نظر بگیرید. در این حالت، تعداد پخشِ آهنگ، متغیر وابسته است و ژانر آهنگ، تعداد دنبالکنندههای هنرمند و مدتزمان آهنگ، متغیرهای مستقل هستند.
رگرسیون لجستیک، مشابه رگرسیون خطی است، با این تفاوت که رگرسیون لجستیک درستی یا نادرستی چیزی یا به بیان تخصصیتر، رابطهی بین متغیرهای مستقل و یک متغیر وابستهی گسسته را پیشبینی میکند. از تابع لجستیک برای پیشبینی احتمالِ نتیجهای خاص، استفاده میکنیم؛ بهعنوان مثال، احتمال آنکه کاربری در اسپاتیفای به آهنگ خاصی علاقه داشته باشد.
تابع لجستیک منحنیای به شکل S است که مقدارهای بین صفر و یک را که نشاندهندهی احتمال وقوع رویداد هستند، تولید میکند. مدل رگرسیون لجستیک از این تابع برای پیشبینی احتمال وقوع رویدادها باتوجهبه مقدارهای متغیرهای مستقل، استفاده میکند. ازآنجاکه این روش، نظارتشده است، برای آموزشِ مدل به مجموعه دادهای شامل متغیرهای مستقل (ویژگیها) و وابسته (خروجی) نیاز داریم. این دادهها به مدل کمک میکنند تا ارتباطِ بین متغیرها را یاد بگیرد.
در مثال اسپاتیفای، متغیر وابسته «دوست داشتن» یا «دوست نداشتن» یک آهنگ است. مدتزمان آهنگ، ژانر و سال انتشار را میتوانید بهعنوان متغیرهای مستقل در نظر بگیرید. مدل رگرسیون لجستیک با استفاده از دادههای آموزشی، الگویی پیدا میکند که رابطهی بین این ویژگیها و احتمال دوست داشتن یا دوست نداشتن آهنگ را نشان میدهد. سپس، با وارد کردن ویژگیهای آهنگِ جدید، مدل میتواند احتمال دوست داشتن آن آهنگ را پیشبینی کند.
همانطور که گفتیم تابع لجستیک، تابعی به شکل S و محدود بین صفر و یک است، در نتیجه میتواند احتمال وقوع یک رویداد را بهخوبی مدلسازی کند. فرض کنید میخواهیم احتمال دوست داشتن آهنگی را براساس میزان شادبودن و ویژگی رقصندگی آن بررسی کنیم. برای رسم نمودار، میزان رقصندگی را روی محور افقی، دوست داشتن یا دوست نداشتن آهنگ را روی محور عمودی، آهنگهایی را که کاربر دوست دارد، با نقاط آبیرنگ و آهنگهایی را که کاربر دوست ندارد، با نقاط قرمزرنگ نشان میدهیم.
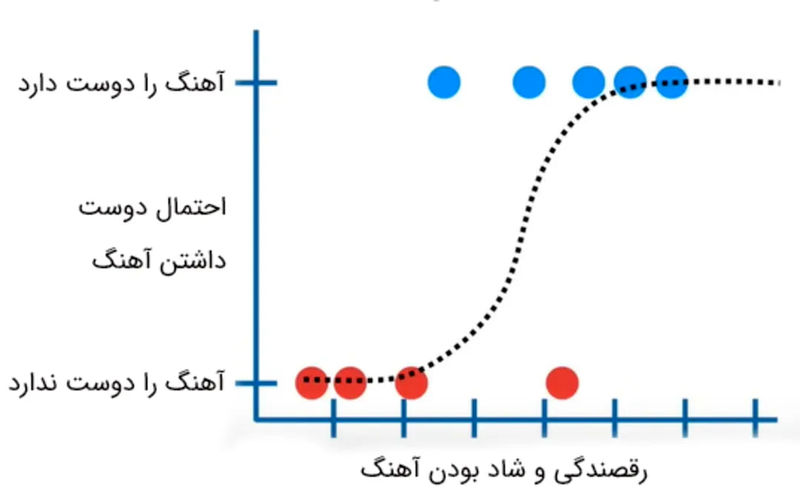
اگرچه رگرسیون لجستیک احتمال علاقهی کاربر را به آهنگی مشخص تخمین میزند، هدف اصلی آن طبقهبندی آهنگها به دو دسته کلی (دوستداشتنی یا دوستنداشتنی) است. بهعنوان مثال، اگر احتمال آنکه کاربری آهنگی رو دوست داشته باشد بیشتر از ۵۰ درصد باشد، آن آهنگ را بهعنوان آهنگِ موردِ پسند و در غیر این صورت بهعنوان آهنگی که موردِ پسند نیست، طبقهبندی میکنیم.
مشابه رگرسیون خطی، در اینجا نیز میتوان مدلهای سادهای ساخت، بهعنوان مثال موردِ پسند بودن آهنگها با میزان رقصندگی آنها پیشبینی میشود. مدلهای ساختهشده حتی میتوانند بسیار پیچیدهتر باشند؛ پیشبینی موردِ پسند بودن آهنگ با میزان رقصندگی و مدت زمان آن.
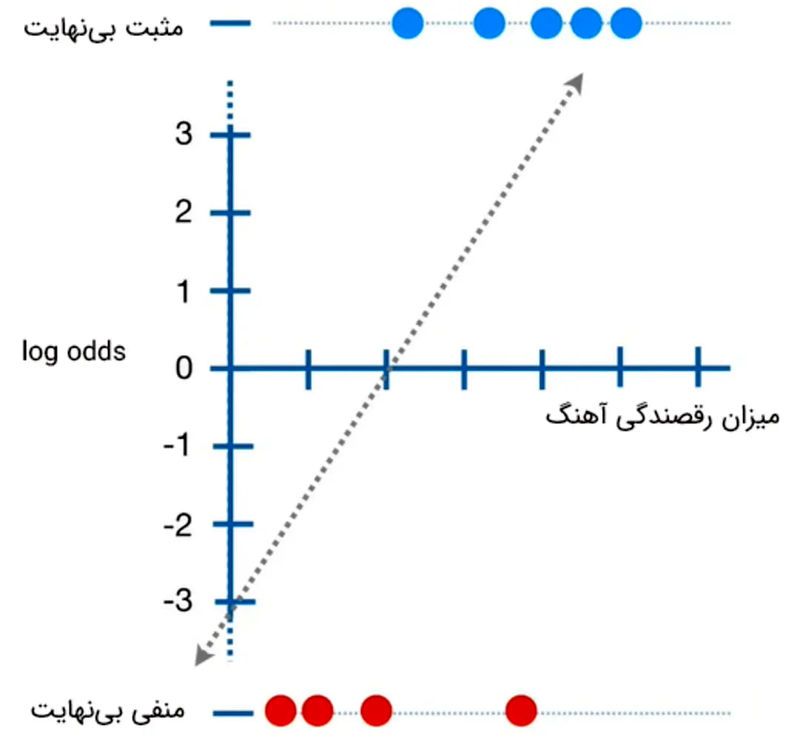
به احتمال زیاد از خود پرسیدهاید چگونه بهترین نمودار S را برای مدلسازی دادههای خود رسم میکنیم. برای انجام این کار محور Y در نمودار فوق که احتمال را نشان میدهد به لگاریتم طبیعیِ نسبت شانس یا لوجیت (log odds یا logit) تغییر میدهیم. هر رویداد با احتمال مشخصی رخ میدهد یا رخ نمیدهد. به نسبت احتمال وقوع یک رویداد و به احتمالِ عدمِ وقوع آن رویداد، نسبت شانس میگوییم.
بهعنوان مثال، کاربری آهنگی را با احتمال ۷۰ درصد دوست دارد و با احتمال ۳۰ درصد آن آهنگ را نمیپسندد. در این حالت، نسبت شانس برابر ۷۰/۳۰ یا ۲٫۳۳ و مقدار لگاریتم طبیعی آن (لوجیت) برابر ۰٫۸۴ است. انجام این کار چه مزایایی دارد؟
قبل از این تبدیل، دادههای محورِ عمودی بین صفر و یک قرار دارند، اما پس از تبدیل به نسبت شانس و گرفتن لگاریتم طبیعی از اعداد بهدستآمده، مقدارهای محور عمودی میتوانند هر مقداری را از منفی بینهایت تا مثبت بینهایت داشته باشند.
پس از تبدیل، رابطهی لگاریتم شانس و ویژگیهای آهنگ مورد نظر بهصورت خطی درمیآید. مدلهای خطی در بیشتر مواقع سادهتر هستند و کار کردن با آنها راحتتر است.
همچنین، با استفاده از تبدیل لگاریتم نسبت شانس بهراحتی میتوانیم آهنگها را طبقهبندی کنیم. اگر این تبدیل مثبت باشد، احتمال آنکه کاربر آهنگ را بپسندد بیشتر از ۵۰ درصد است. در این صورت آهنگ را میتوان در دستهی آهنگهای مورد پسند کاربر قرار داد. در مقابل، اگر لگاریتم نسبتِ شانس منفی باشد، احتمال آنکه آهنگ مورد پسند کاربر باشد، کمتر از ۵۰ درصد خواهد بود. در نتیجه، آهنگ در دستهی آهنگهایی قرار میگیرد که کاربر دوست ندارد.
تابع لجستیک به شکل زیر نوشته میشود:
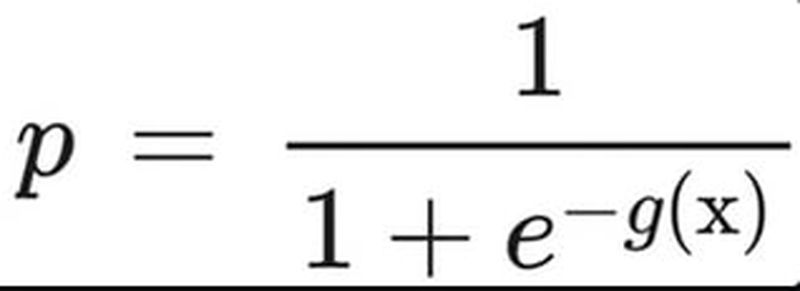
در این فرمول، p احتمال وقوع یک رویداد مانند احتمال آنکه کاربر آهنگی را دوست داشته باشد، است. همچنین، g(x) بهصورت ترکیب خطی متغیرهای مستقل، مانند ویژگیهای آهنگ، نوشته میشود. e نیز عدد نپر نام دارد و مقدار آن برابر ۲٫۷۱۸ است. مخرج کسر، 1 + e^ (-g(x))، تابع را به شکل S درمیآورد و محور عمودی را بین صفر و یک محدود میکند. اگر g(x) بسیار بزرگ باشد، مقدار e^ (-g(x)) برابر صفر و مقدار وقوع رویداد به یک نزدیک میشود. در مقابل، اگر e^ (-g(x)) بسیار کوچک باشد، احتمال وقوع یک رویداد بسیار کوچک خواهد بود.
همانطور که اشاره کردیم هر آهنگ ویژگیهای مختلفی مانند ژانر، مدتزمان پخش، میزان شاد بودن و غیره دارد. بنابراین، هر آهنگ در اسپاتیفای را میتوانیم بهعنوان برداری با n مؤلفه در نظر بگیریم که هر مؤلفه یکی از ویژگیهای آن را نشان میدهد.
نمایش هر آهنگ به عنوان بردار
بهعنوان مثال، اگر سه ویژگی مانند ژانر، تعداد دنبالکنندهها و مدتزمان آهنگ برای ما مهم باشند، بردار x سه مؤلفه خواهد داشت و هر مؤلفه یکی از ویژگیها را نشان میدهد. کاربر با چه احتمالی آهنگ مورد نظر را میپسندد؟ p(x) یا همان تابع لجستیک. برای آنکه بتوانیم تابع s را بهصورت خطی رسم کنیم، تابع لوجیت را برحسب p(x) بهصورت زیر مینویسیم:
Odds = p(x) / (1 - p(x))
با قرار دادن تابع p(x) در رابطهی فوق و گرفتن ln از آن به رابطهی خطیای که در نظر داریم، میرسیم. در واقع با انجام این کار مدل سادهتر میشود و میتوانیم از تکنیکهای خطی برای تجزیه و تحلیل دادهها استفاده کنیم. در این حالت، g(x) تابع لگاریتم نسبت شانس را نشان میدهد که یک طبقهبندی خطی است و رابطهی بین ویژگیهای آهنگ و احتمال دوست داشتنِ آن را بهصورت خطی مدلسازی میکند. به بیان دیگر، g(x) یک ترکیب خطی از ویژگیهای آهنگ و وزنِ آنها است.
بردار وزن (Weight Vector یا w) در رگرسیون لجستیک نقش بسیار مهمی را ایفا و به ما کمک میکند تا اهمیت هر یک از ویژگیها را در پیشبینی نتیجهی نهایی درک کنیم. با بررسی بردار وزن، میتوانیم بفهمیم که کدام ویژگیها در پیشبینی نتیجهی نهایی مهمتر هستند. همانطور که گفتیم g(x) را میتوانیم بهصورت ترکیب خطی ویژگیهای مختلف آهنگ و وزنِ مربوط به هر ویژگی بنویسیم.
برای یافتن خط بهترین برازش، باید وزنهای w را تخمین بزنیم. بهطور معمول، این کار را میتوان به کمک روشهای آماری مانند حداقل مربعات انجام داد. خط بهترین برازش خطی است که بهترین تناسب را با دادههای آموزشی دارد و به ما کمک میکند تا پیشبینیهای دقیقتری برای آهنگهای جدید انجام دهیم.
به کمک روشی به نام برآورد درستنمایی بیشینه یا برآورد احتمال بیشینه (Maximum Likelihood Estimation یا MEL) میتوانیم طبقهبندی خطی دقیقی برای منحنی لجستیک نهایی پیدا کنیم. MLE روشی برای تعیین بهترین پارامترهای یک مدل (در اینجا، وزنهای w در مدل لجستیک) است. به بیان ساده، MLE به ما کمک میکند بهترین پارامترها را برای یک مدل پیدا کنیم تا این مدل بتواند دادههای مشاهدهشده را به بهترین شکل ممکن توضیح دهد. MLE به دنبال یافتن بهترین وزنها برای منحنی S است تا دادههای آموزشی ما بیشترین تطابق را با آن داشته باشند.
ازآنجاکه اگر کاربری آهنگی را دوست داشته باشد، مستقل از دوست داشتن یا دوست نداشتن آهنگهای دیگر توسط آن کاربر است، احتمال کل را با ضرب احتمالات برای هر نقطه داده میتوانیم محاسبه کنیم؛ همچنین، احتمال آنکه کاربری آهنگی را بپسندد یا نپسندد با توزیع برنولی بیان میشود. توزیع برنولی یک توزیع احتمال برای رویدادهایی است که از دو حالت، مانند پسندیدن یا نپسندیدن یک آهنگ، تشکیل شدهاند.
تابع درستنمایی و لگاریتم آن بهصورت زیر نوشته میشوند:

تابع درستنمایی، احتمال مشاهدهی دادهها را با توجه به پارامترهای فعلی مدل (w) محاسبه میکند. در واقع، هدف یافتن پارامترهایی است که احتمال را به حداکثر برساند. این فرمول نشان میدهد که تابع درستنمایی برابر با حاصلضرب احتمال هر نمونه در دادههای ما است.
به احتمال زیاد از خود پرسیدهاید چرا لگاریتم تابع درستنمایی محاسبه میشود. لگاریتم حاصلضرب چند عبارت در یکدیگر، برابر مجموع لگاریتم هر یک از عبارتها با یکدیگر است. با انجام این کار محاسبات سادهتر میشود. لگاریتم تابع درستنمایی معمولاً تابعی محدب محسوب میشود که به ما اجازه میدهد از روشهای بهینهسازی عددی برای یافتن بیشینهی آن استفاده کنیم.
چگونه تابع درستنمایی و لگاریتم آن را میتوانیم بیشینه کنیم؟ با گرفتن مشتق جزیی نسبت به w و برابرِ صفر قرار دادن مشتق. متأسفانه، معادلهی حاصل از مشتق جزیی را در این مورد را نمیتوانیم بهصورت مستقیم حل کنیم. بههمیندلیل، باید از روشهای عددی مانند شیب، نزولی یا روش نیوتن-رافسون استفاده کنیم تا وزنها را بهطور تقریبی بهدست آوریم.
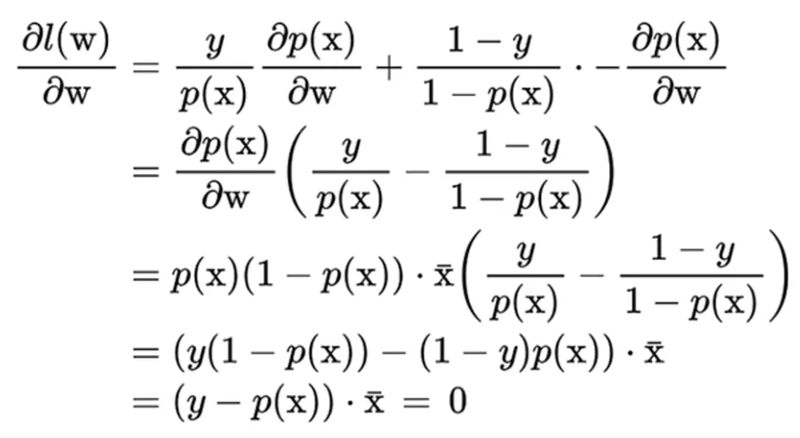
برای درک بهتر این موضوع مثال سادهای را با یکدیگر بررسی میکنیم. فرض کنید در اسپاتیفای به ۱۰ آهنگِ مختلف گوش دادهاید و هفت آهنگ را پسندیدهاید و سه آهنگ را دوست نداشتهاید. برای استفاده از مدل MLE ابتدا باید مدل احتمالی خود را تعریف کنیم. همانطور که گفتیم پسندیدن یک آهنگ توسط کاربر مستقل از دوست داشتن یا دوست نداشتن آهنگهای دیگر توسط آن کاربر است. احتمال آنکه کاربر k آهنگ از n آهنگ را پسندیده باشد، بهصورت زیر بیان میشود:
فرمول یک مثال
در رابطهی فوق مقدار k برابر ۷ و مقدار n برابر ۱۰ است. بهراحتی با گرفتن لگاریتم طبیعی از رابطهی فوق، گرفتن مشتق و برابرِ صفر قرار دادنِ مشتق، مقدار p را برابر ۰٫۷ بهدست میآید. این بدان معنا است که اگر به آهنگ جدیدی گوش دهیم، براساس دادههای گذشته به احتمال ۷۰ درصد آن را دوست خواهیم داشت.
این مثالِ ساده به ما نشان میدهد که چگونه میتوان با استفاده از روش رگرسیون لجستیک و MLE، میزان علاقهی افراد را به آهنگهای مختلف تخمین زد. این روش به اسپاتیفای کمک میکند تا با استفاده از دادههای قبلی (آهنگهایی که پسندیدهاید یا نپسندیدهاید)، بهترین پارامترها را برای مدلسازی علاقهمندی کاربرها پیدا کند. سپس، اسپاتیفای به کمک این تخمین میتواند آهنگهای مختلف را به کاربران پیشنهاد دهد.
ماشین بردار پشتیبان
ماشین بردار پشتیبان (Support Vector Machine یا SVM) یکی از الگوریتمهای یادگیری ماشین بهشمار میرود که بهطور گسترده برای طبقهبندی دادهها استفاده میشود. این الگوریتم با پیدا کردن بهترین مرز تصمیمگیری بین دادهها، آنها را به کلاسهای مختلف تقسیم میکند. اسپاتیفای نیز بهعنوانِ پلتفرم پخش موسیقی، حجم عظیمی از داده دارد که شامل اطلاعاتی در مورد آهنگها و کاربران است. از این دادهها میتوانیم برای آموزش مدلهای یادگیری ماشین مانند SVM استفاده کنیم.
واپنیک و همکارانش SVM را اوایل دههی ۹۰ میلادی در آزمایشگاههای بل AT&T توسعه دادند. این آزمایشگاه یکی از مراکز مهم تحقیقاتی در زمینهی ارتباطات و فناوری اطلاعات بود که بسیاری از فناوریهای نوین در آن توسعه یافتهاند. الگوریتم ماشین بردار پشتیبان بر پایهی اصول یادگیری آماری استوار و از آن زمان تاکنون به یکی از پرکاربردترین الگوریتمهای یادگیری ماشین تبدیل شده است.
الگوریتم SVM به دنبال یافتن یک ابرصفحهی بهینه است که دادهها را به دو یا چند کلاس مختلف به شکلی دقیق و تعمیمپذیر تقسیم کند. ابرصفحه خط یا مزر در فضای دوبعدی یا یک صفحه در فضای سهبعدی است که دادهها را از هم جدا میکند.
فرض کنید تعدادی داده داریم که ویژگیهای مختلف آهنگها در اسپاتیفای را نشان میدهد. برای سادگی، تنها یک ویژگی را در نظر میگیریم؛ تمپو یا تندا معیاری از سرعت اجرای قطعههای موسیقی و تعداد ضرب در دقیقه است. دایرههای قرمزرنگ آهنگهای آرام را با تعداد ضربِ کم در دقیقه و دایرههای سبزرنگ آهنگهای تند را با تعداد ضربِ زیاد در دقیقه نشان میدهند.

براساس آهنگهای شنیدهشده میتوانیم آستانهای را برای تعیین نوع آهنگهای جدید تعیین کنیم. در این حالت، تعداد ۱۰۰ ضرب در دقیقه را میتوانیم بهعنوان آستانه انتخاب کنیم. بنابراین، هر آهنگِ جدیدی با تعداد بیش از ۱۰۰ ضرب در دقیقه را میتوان در گروه آهنگهای سریع و تعداد کمتر از ۱۰۰ ضرب در دقیقه را در گروه آهنگهای آرام طبقهبندی کرد.

حال فرض کنید آهنگ جدید در نزدیکی خط آستانه قرار داشته باشد.

ازآنجاکه تمپوی آهنگِ جدید (دایرهی سیاهرنگ) بزرگتر از ۱۰۰ است، آن را در گروه آهنگهای سریع قرار میدهیم؛ اما این دستهبندی منطقی به نظر نمیرسد، زیرا آهنگِ جدید به آهنگهای آرام نزدیکتر است. در نتیجه، اینگونه به نظر میرسد که آستانهی انتخابشده زیاد جالب نیست. برای آنکه انتخاب بهتری برای آستانه داشته باشیم، بار دیگر به دادههای دو دسته نگاه و توجه خود را روی مشاهداتِ لبه متمرکز میکنیم. بنابراین، انتخاب نقطهی میانی بهعنوان آستانه، انتخاب منطقیتری به نظر میرسد.
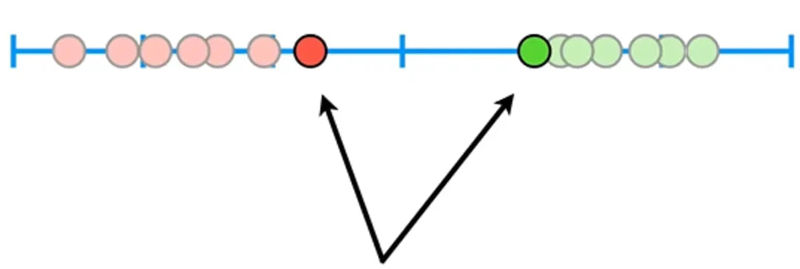
در این حالت، آهنگ جدید سمت چپ آستانه و در گروه آهنگهای آرام قرار میگیرد.
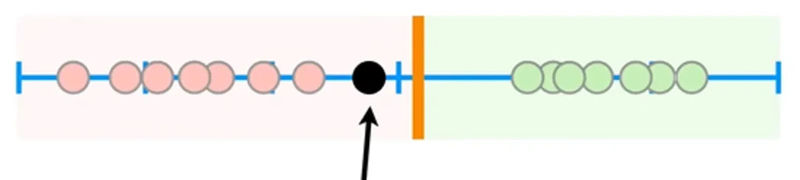
به کوتاهترین فاصله بین تمپوی آهنگهای گوشدادهشده و آستانه، حاشیه (Margin) میگوییم.
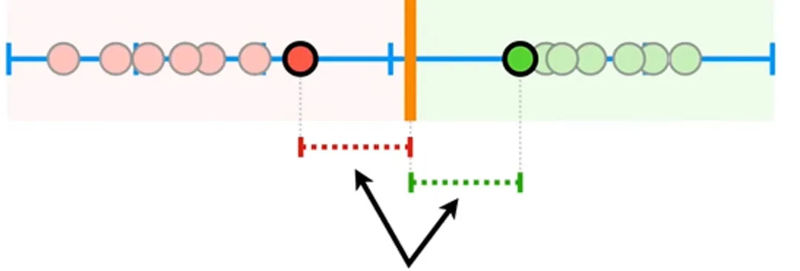
هنگامی که آستانه وسط دو آهنگ قرار بگیرد، حاشیه بزرگترین مقدار خود را دارد که به آن حاشیهی حداکثری میگوییم. اگر آستانه را در تصویر فوق، کمی به سمت چپ حرکت دهیم، فاصلهی بین خطِ آستانه و آهنگهای آرام و در نتیجه مقدار حاشیه کوچکتر میشود. بهطور مشابه، اگر آستانه را در تصویر فوق، کمی به سمت راست حرکت دهیم، فاصلهی بین خط آستانه و آهنگهای تند و در نتیجه مقدار حاشیه کوچکتر خواهد شد.
اگر آستانه را به گونهای انتخاب کنیم که بزرگترین حاشیه را نسبت به هر دو دسته آهنگ به ما بدهد، از روشی به نام طبقهبندیکنندهی حاشیهی حداکثری (Maximum Margin Classifier) استفاده کردهایم. این روش زمانی به خوبی عمل میکند که دادهها تمیز و بدون نویز باشند؛ اما اگر دادههای مربوط به تمپوی آهنگها به گونهای باشد که یک یا چند آهنگ تفاوت زیادی با سایر آهنگها داشته باشند (دادههای پرت)، این روش بهدرستی عمل نخواهد کرد؛ زیرا روش طبقهبندیکنندهی حاشیهی حداکثری نسبت به دادههای پرت بسیار حساس است و وجود چنین دادههایی میتواند مرز تصمیمگیری را بهطور قابل توجهی تغییر دهد.
آیا راه بهتری وجود دارد؟ بله. برای انتخاب آستانهای که نسبت به دادههای پرت حساس نباشد باید به این موضوع توجه داشته باشیم که شاید برخی دادهها به اشتباه طبقهبندی شوند. وقتی دادهی پرتی در نزدیکی مرز بین دو دسته قرار دارد، ممکن است بهاشتباه به دسته دیگری نسبت داده شود. این اتفاق به این دلیل رخ میدهد که مرزی که ما برای تقسیم دادهها انتخاب کردهایم، میتواند به اندازهی کافی دقیق نباشد و دادههای پرت را به درستی طبقهبندی نکند.
انتخاب آستانهی مناسب در یادگیری ماشین تصمیمی مهم و پیچیده است که مستقیماً بر عملکرد مدل تأثیر میگذارد. برای انتخاب بهترین آستانه، باید به عوامل مختلفی مانند نوع دادهها، الگوریتم مورد استفاده و هدف مدلسازی توجه کرد. تا اینجا در مورد آهنگهایی صحبت کردیم که یکی از ویژگیهای آنها، تمپو، مورد توجه است. در این حالت، آهنگها را میتوانیم روی خطی افقی (یک بعد) قرار دهیم و از نقطه برای جداسازی و طبقهبندی آنها استفاده کنیم.
حال فرض کنید علاوه بر تمپو، ویژگی دیگری مانند مدت زمان آهنگ را نیز در نظر میگیریم. در این حالت، تمپو را روی محور افقی و مدت زمان آهنگ را روی محور عمودی رسم میکنیم. در فضای دوبعدی، دادهها به کمک خط از یکدیگر جدا میشوند. برخی دادههای جمعآوریشده در اسپاتیفای را میتوان به کمک خط از یکدیگر جدا کرد، اما برخی دادهها را به کمک هیچ خطی نمیتوانیم جدا کنیم.
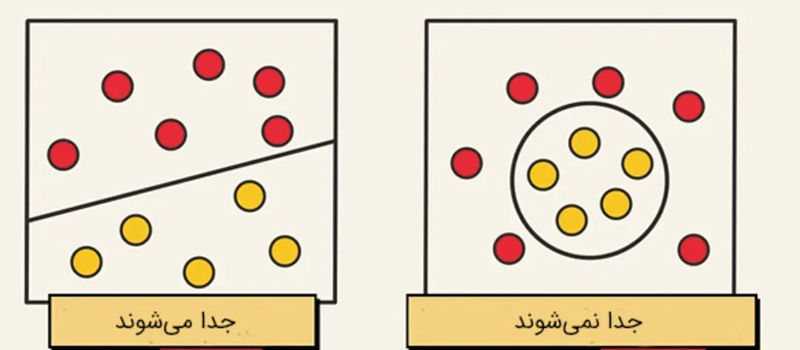
اجازه دهید نگاه نزدیکتری به دادههایی که در تصویر بالا به کمک خط از یکدیگر جدا میشوند، داشته باشیم. راههایی زیادی برای جدا کردن این دادهها به کمک خط وجود دارند، اما بهترین راه کدام است؟ به کمک الگوریتم ماشین بردارِ پشتیبان میتوانیم بهترین ابرصفحه (در اینجا خط) را بهگونهای انتخاب کنیم که حاشیه نیز بیشینه شود.
به دادههایی که در نزدیکترین فاصله از ابرصفحه قرار دارند، بردارهای پشتیبان میگوییم. به بیان ساده، دادههای مرزی را میتوانیم بهعنوان بردارهای پشتیبان در نظر بگیریم. طبقهبندی این دادهها بسیار سختتر از دادههای دیگر است و همانطور که اشاره کردیم به کمک آنها میتوانیم آستانه یا ابرصفحه را انتخاب کنیم.
برخلاف دیگر الگوریتمهای یادگیری ماشین که تمام دادهها بر بهینهسازی و تصمیمگیری نهایی مؤثر هستند، در الگوریتم ماشین بردار پشتیبان، تنها بردارهای پشتیبان بر تصمیمگیری نهایی تأثیر میگذارند. اگر دادههای مرزی جابهجا شوند، ابرصفحه نیز تغییر خواهد کرد.
بار دیگر به مثال دستهبندی آهنگها براساس تمپو و مدت زمان پخش آهنگ برمیگردیم. هر آهنگ را بهعنوان یک نقطه در فضای دوبعدی در نظر میگیریم که هر بعد ویژگی خاصی را نشان میدهد. برخی آهنگها را بهراحتی میتوانیم با خط از یکدیگر جدا کنیم، اما تمپو و مدتزمان برخی آهنگها بهگونهای است که به راحتی نمیتوانیم آنها را به کمک خطی ساده در فضای دوبعدی از یکدیگر جدا کنیم (تصویر زیر). در این حالت، از توابعی به نام توابع کرنل استفاده میکنیم.
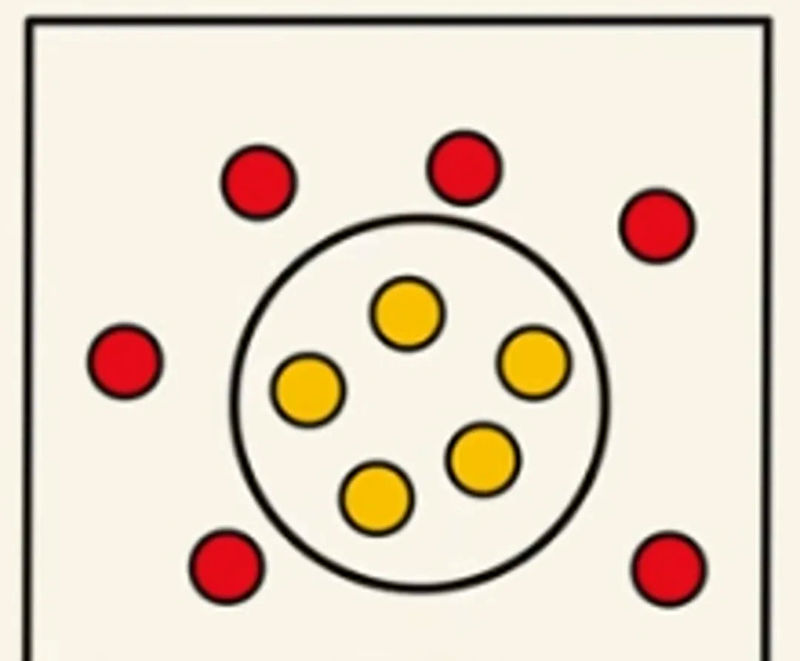
به کمک این توابع میتوانیم دادهها را به یک فضای بالاتر (بعد جدید) منتقل کنیم. چگونه با توابع کرنل میتوانیم این کار را انجام دهیم؟ توابع کرنل بهطور مستقیم ضرب داخلی نقاط داده را در فضای جدید محاسبه میکنند. این روش بسیار کارآمد است و از پیچیدگی محاسباتی میکاهد. انتخاب تابع کرنل مناسب به نوع دادهها و مسئله بستگی دارد. کرنلهای مختلف، نگاشتهای متفاوتی را به فضایی با ابعاد بالاتر ایجاد میکنند.
بوستینگ
بوستینگ (Boosting) یک روش یادگیری ماشین است که با ترکیب چند یادگیرندهی ضعیف (weak learner)، یک یادگیرندهی قوی (strong learner) ایجاد میکند. فرض کنید اسپاتیفای میخواهد سیستمی بسازد که آهنگها را براساسِ علایقِ کاربران به آنها پیشنهاد دهد. هر یادگیرندهی ضعیف میتواند مدلِ سادهای باشد که آهنگهای جدید را براساس ژانر موسیقی، هنرمند یا زمان گوش دادن شما به هر آهنگ، پیشنهاد دهد.
بوستینگ با ترکیب این مدلها، مدل پیچیدهتر و دقیقتری میسازد. اگر هر مدل ساده آهنگی را به شما پیشنهاد داد که دوست نداشتید، مدلهای جدید تلاش بیشتری میکنند تا آهنگهایی نزدیک به سلیقهی شخصی شما، پیشنهاد دهند. مزایای استفاده از بوستینگ در اسپاتیفای عبارتاند از:
شخصیسازی بالا: باتوجهبه آهنگهایی که کاربر قبلاً گوش داده است، پیشنهادهای بسیار شخصیسازی شدهای ارائه میدهد.
کشف موسیقی جدید: به کاربران کمک میکند تا با ژانرهای جدید و هنرمندان جدید آشنا شوند.
دقت بالا: با ترکیب چندین مدل، دقت پیشبینیها افزایش مییابد.
انعطافپذیری: از بوستینگ میتوان برای انواع دادهها و مسائل استفاده کرد.
از نظر ریاضی بوستیگ را میتوانیم بهصورت زیر بنویسیم که در آن هر مدل ساده وزنی با مقداری مشخص دارد و مقدار وزن، متناسب با اهمیت مدل در پیشبینی نهایی است. پیشبینی نهایی با استفاده از تابع علامت (sign)، به یک مقدار مثبت یا منفی تبدیل میشود که کلاس یا دستهی پیشبینی را نشان میدهد.
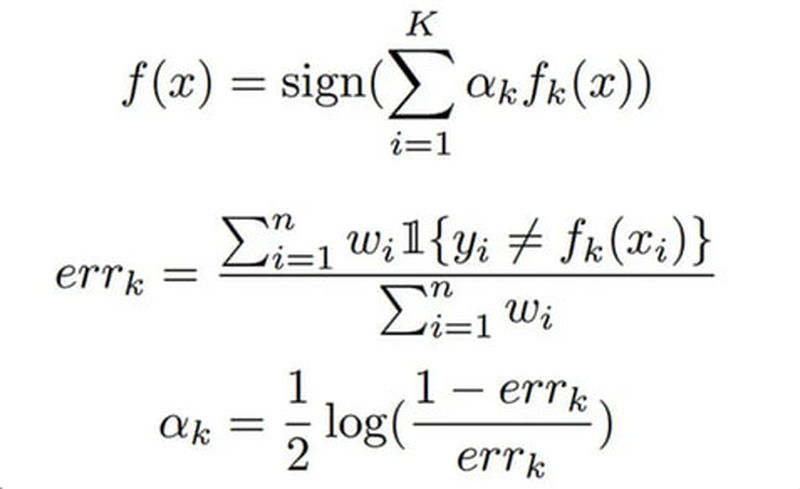
چگونه وزن هر مدل ضعیف تعیین میشود؟ برای پاسخ به این سؤال، از مفهوم زیان نمایی (Exponential loss) و بهینهسازی استفاده میکنیم. تابع زیان نمایی، به خطاهای مدل، حساسیت بسیار بالایی نشان میدهد. در واقع، هرچه مدل در پیشبینی یک نمونه بیشتر اشتباه کند، مقدار زیان آن نمونه بهصورت تصاعدی افزایش مییابد. این به معنای آن است که الگوریتم بوستینگ به نمونههایی که به سختی قابل طبقهبندی هستند، توجه ویژهای میکند و با بزرگنمایی وزن این نمونهها، به مدل فشار میآورد تا در تکرارهای بعدی، آنها را به درستی طبقهبندی کند.
پیشبینی نهایی بهصورت ترکیبی از پیشبینیهای مدلهای ضعیف است، بهطوریکه مدلهایی که عملکرد بهتری داشتند، وزن بیشتری در تصمیمگیری نهایی ایفا میکنند. بدین صورت خطاهای مدلهای ضعیف تا حد امکان کاهش و عملکرد کلی مدل افزایش مییابد.
تا اینجا با مهمترین الگوریتمهایی که اسپاتیفای یا سیستمهای مشابه میتوانند برای معرفی آهنگ به کاربر استفاده کنند، آشنا شدیم. برای استفاده از این الگوریتمها در اسپاتیفای ابتدا باید مجموعهای از دادههای آموزشی و آزمایشی ایجاد کنیم. این مجموعهی داده از آهنگهایی که «پسندیده شده» و «پسندیده نشده» به همراه سایر آهنگهای داخل مجموعه تشکیل شده است.
در این حالت، مجموعه دادهی آموزشی شامل آهنگهایی با برچسبهای «پسندیده شده» و «پسندیده نشده» میشود و هدف از انجام این کار آن است که مدل بداند کاربر بر چه اساسی آهنگهای مودعلاقهی خود را انتخاب میکند. آهنگهای جدید نیز در مجموعه دادهی آزمایشی قرار میگیرند. سپس، از مدلهای موجود در پکیجهای sklearn پایتون استفاده میکنیم تا مدل را آموزش دهیم و مجموعه دادهی آزمایشی را طبقهبندی و لیستی از آهنگهای مورد علاقهی کاربر و آهنگهایی که علاقه ندارد، تولید کنیم.
در مثالِ زیر، ۱ آهنگِ مورد علاقهی کاربر را نشان میدهد و ۱- آهنگی را نشان میدهد که کاربر نپسندیده است. دادههای ورودی در جدول زیر نشان داده شدهاند.
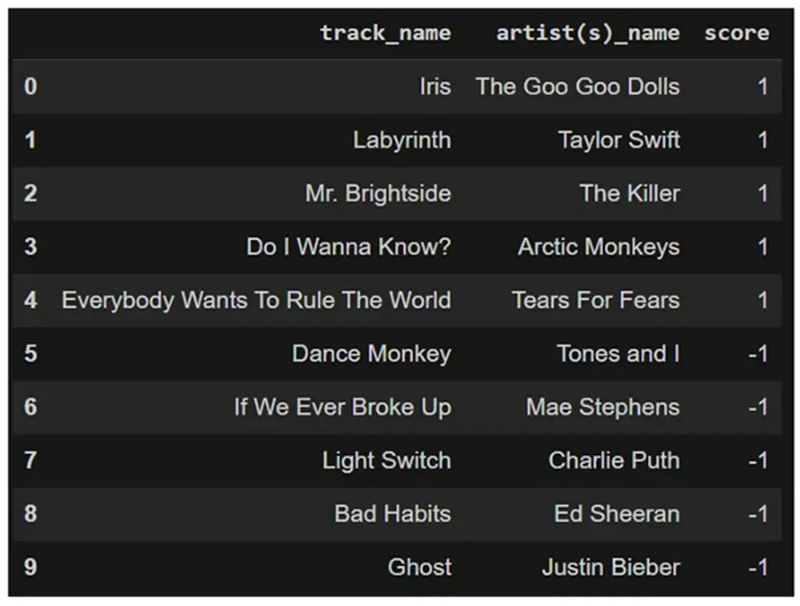
Medium
هر یک از سه الگوریتمی که بالاتر در مورد آنها صحبت کردیم، خروجی متفاوتی را به ما میدهد.
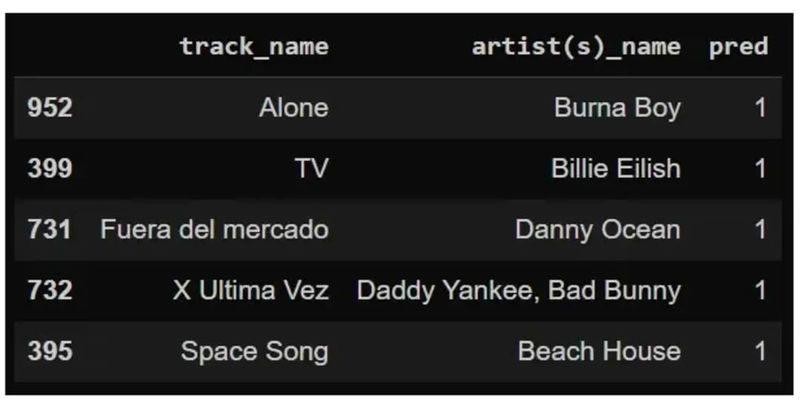
الگوریتم رگرسیون لجستیک
Medium
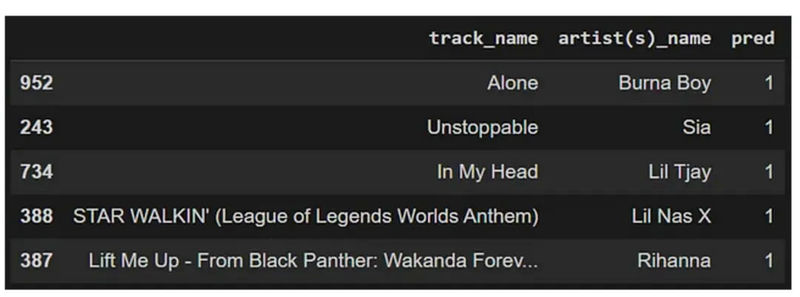
الگوریتم SVM
Medium
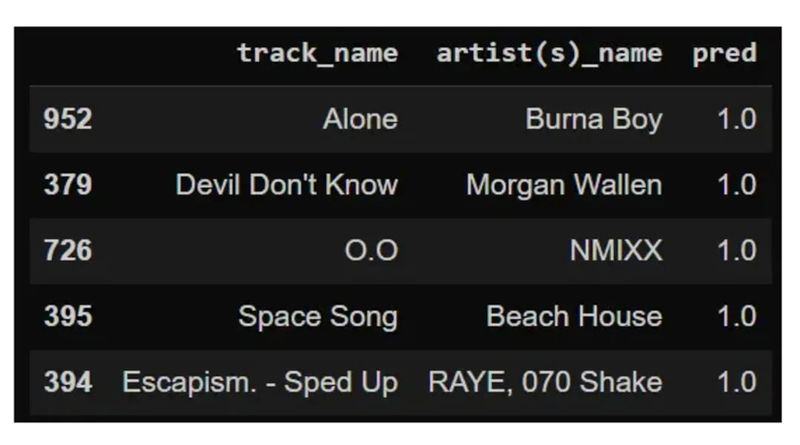
الگوریتم بوستینگ
Medium
با استفاده از تکنیکهای پردازش زبان طبیعی یا NLP نیز میتوانیم ویژگیهای مبتنیبر متن ترانهها را استخراج و برای بهبود مدل پیشنهاد موسیقی در اسپاتیفای استفاده کنیم. اسپاتیفای از مدلهای NLP برای تحلیل اشعار و اطلاعات جمعآوریشده از پلیلیستهای کاربران استفاده میکند تا درک بهتری از موسیقی و توصیفی که کاربران از آن دارند، بهدست آورد. اسپاتیفای با انجام این کار میتواند آهنگها را بهتر تحلیل کند و پیشنهادهای دقیقتری به کاربران بدهد.
در دنیای امروز، یافتن آهنگهای مورد علاقه میتواند بسیار چالشبرانگیز باشد. همانطور که دیدیم، اسپاتیفای با استفاده از الگوریتمهای پیچیدهی متشکل از تحلیل ویژگیهای صوتی، متادیتا، دادههای مربوط به تعامل کاربران و تکنیکهای پیشرفتهی یادگیری ماشین، این چالش را به فرصتی برای کشف آهنگهای جدید و شخصیسازی تجربهی شنیداری تبدیل کرده است.
با تحلیل عمیق دادههای کاربران، اسپاتیفای میتواند الگوهای شنیداری را شناسایی کند و با استفاده از این الگوها، آهنگهایی را پیشنهاد دهد که احتمالاً مورد علاقهی کاربر خواهد بود. این رویکرد، محدودیتهای شنیداری را از بین میبرد و به کاربران اجازه میدهد تا به دنیای بیکران موسیقی سفر کنند.
منبع: زومیت
-
ببینید / محل تلاقی رودهای آرمند و کارون در چهارمحال و بختیاری

ارسال نظر